
Running High Scale Low Latency Database with Zero Data In Memory?
I was talking to one of my oldest database colleagues (and a very dear friend of mine). We were chatting about how key/value stores and databases are evolving. My friend mentioned how they always seem to be revolving around in-memory solutions and cache. The main rant was how this kind of thing doesn’t scale well, while being expensive and complicated to maintain.
My friend’s background story was that they are running an application that uses a user profile with almost 700 million profiles (their total size was around 2TB, with a replication factor of 2). Since the access to the user profile is very random. In short terms, it means, the application is not able to “guess” which user it would need next as that is pretty much random. Therefore, they could not use pre-heating of the data to memory. Their main issue was that every now and then they were getting high peaks of over 500k operations per second of this kind of mixed workloads and that didn’t scale very well.
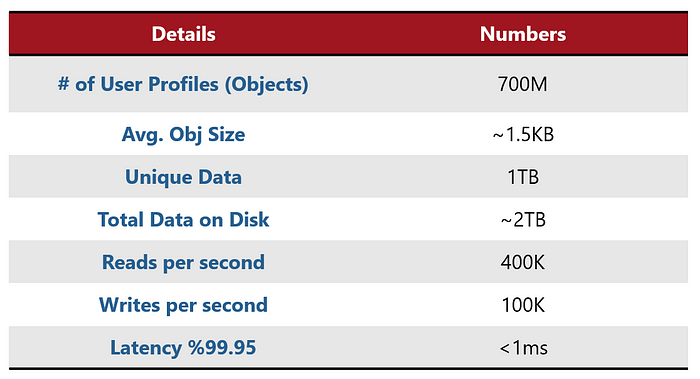
User Profile use case summary
