Spark SQL and Oracle Database Integration
I’ve been meaning to write about Apache Spark for quite some time now – I’ve been working with a few of my customers and I find this framework powerful, practical, and useful for a lot of big data usages. For those of you who don’t know about Apache Spark, here is a short introduction.
Apache Spark is a framework for distributed calculation and handling of big data. Like Hadoop, it uses a clustered environment in order to partition and distribute the data to multiple nodes, dividing the work between them. Unlike Hadoop, Spark is based on the concepts of in-memory calculation. Its main advantages are the ability to pipeline operations (thus breaking the initial concept of a single map-single reduce in the MapReduce framework), making the code much easier to write and run, and doing it in an in-memory architecture so things run much faster.
Hadoop and Spark can co-exist, and by using YARN – we get many benefits from that kind of environment setup.
Of course, Spark is not bulletproof and you do need to know how to work with it to achieve the best performance. As a distributed application framework, Spark is awesome – and I suggest getting to know with it as soon as possible.
I will probably make a longer post introducing it in the near future (once I’m over with all of my prior commitments).
In the meantime, here is a short explanation about how to connect from Spark SQL to Oracle Database.
Update: here is the 200 long slides presentation I made for Oracle Week 2016: it should cover most of the information new comers need to know about spark.
Spark presentation from Oracle Week 2016.
Connecting Spark with Oracle Database
Before we actually begin connecting Spark to Oracle, we need a short explanation on Spark’s basic building block, which is called RDD – Resilient Distributed Dataset. RDD is a data structure that is being distributed across the cluster, but from the developer perspective, there is no need to know how and where the data is. Every operation we do to the data is being distributed and collected back whenever we need it.
Using Spark Core, most RDDs are being built from files – they can be on the local driver machine, Amazon S3, and even HDFS – but never the less, they are all files. We can also build RDDs from other RDDs by manipulating them (transform functions).
Spark SQL
We can build RDDs from files, and that’s great, but files is not the only source of data out there. We know that sometime we keep our data in a more complex data stores: it can be relational databases (Oracle, MySQL, Postgres), it can be NoSQL (Redis, Oracle NoSQL etc.), JSON datasets, and it can even be on data structures that are native to Hadoop – Hbase and Hive to name a few. Most of those structures, allow retrieving of the data in a language we already know (SQL) – but Spark didn’t allow building RDDs from that and a new module was born, Spark SQL (Shark, in earlier versions).
The Spark SQL module allows us the ability to connect to databases and use SQL language to create new structure that can be converted to RDD. Spark SQL is built on two main components: DataFrame and SQLContext.
The SQLContext encapsulate all relational functionality in Spark. When we create the SQLContext from the existing SparkContext (basic component for Spark Core), we’re actually extending the Spark Context functionality to be able to “talk” to databases, based on the connecter we provide.
DataFrame is a distributed collection of data organized into named columns. This will be the result set of what we read from the database (table). The nice thing about DF is that we can convert it to RDD, and use Spark regular functionality; we can manipulate the data in it just like any other RDD we load into Spark.
Using Spark with Oracle RDBMS
The first thing we need to do in order to use Spark with Oracle is to actually install Spark framework. This is a very easy task, even if you don’t have any clusters. There is no need for Hadoop installation or any kind of framework, other than Spark binaries.
The first step is to go to Spark download page and download a package. In my example, I used Pre-Built for Hadoop 2.6. This means that we don’t need Hadoop cluster – the Spark installation will come with all of its Hadoop prerequisites.
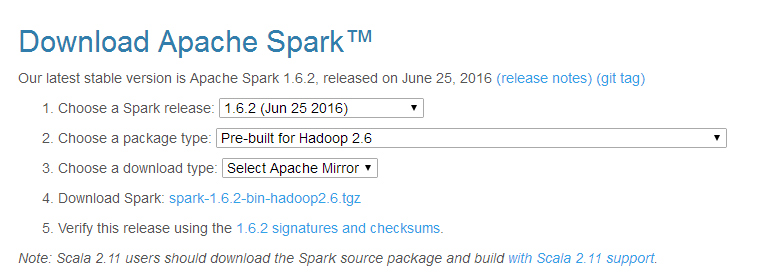
Once we get the file, we can deploy the Spark on our server:
-rw-r--r--. 1 oracle oinstall 278057117 Jul 3 15:30 spark-1.6.2-bin-hadoop2.6.tgz [oracle@lnx7-oracle-1 spark]$ tar xzvf spark-1.6.2-bin-hadoop2.6.tgz spark-1.6.2-bin-hadoop2.6/ […]
We can now go to the Spark directory and start the master server. The master in Spark is the component that is in charge of distributing the work between Spark workers (or slaves):
[oracle@lnx7-oracle-1 spark]$ cd spark-1.6.2-bin-hadoop2.6/ [oracle@lnx7-oracle-1 spark-1.6.2-bin-hadoop2.6]$ cd sbin/ [oracle@lnx7-oracle-1 sbin]$ ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /home/oracle/spark/spark-1.6.2-bin-hadoop2.6/logs/spark-oracle-org.apache.spark.deploy.master.Master-1-lnx7-oracle-1.out
Once the master has started, we can start a worker node as well. This worker will need to know the master node:
[oracle@lnx7-oracle-1 sbin]$ ./start-slave.sh spark://localhost:7077 starting org.apache.spark.deploy.worker.Worker, logging to /home/oracle/spark/spark-1.6.2-bin-hadoop2.6/logs/spark-oracle-org.apache.spark.deploy.worker.Worker-1-lnx7-oracle-1.out
We now have a (small) working Spark Standalone Cluster. The standalone in this part refer to the fact that there is no external resource manager such as YARN, not that the node is stand-alone.
Our next step will be providing the Spark environment with the classpath for the JDBC driver we’re going to use. I used Oracle 12c I had installed on that server – but we can use any driver and any system we like here:
[oracle@lnx7-oracle-1 bin]$ export SPARK_CLASSPATH=/u01/app/oracle/product/12.1.0/dbhome_12102/jdbc/lib/ojdbc7.jar
Using Spark SQL and Spark Shell
Once we have everything in place, we can use the Spark Shell (Scala based interpreter) to connect to the database and query some tables:
[oracle@lnx7-oracle-1 bin]$ ./spark-shell
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.2
/_/
Using Scala version 2.10.5 (OpenJDK 64-Bit Server VM, Java 1.8.0_65)
Type in expressions to have them evaluated.
Type :help for more information.
16/07/03 16:14:04 WARN Utils: Your hostname, lnx7-oracle-1 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
16/07/03 16:14:04 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
16/07/03 16:14:04 WARN SparkConf:
SPARK_CLASSPATH was detected (set to '/u01/app/oracle/product/12.1.0/dbhome_12102/jdbc/lib/ojdbc7.jar').
This is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with --driver-class-path to augment the driver classpath
- spark.executor.extraClassPath to augment the executor classpath
16/07/03 16:14:04 WARN SparkConf: Setting 'spark.executor.extraClassPath' to '/u01/app/oracle/product/12.1.0/dbhome_12102/jdbc/lib/ojdbc7.jar' as a work-around.
16/07/03 16:14:04 WARN SparkConf: Setting 'spark.driver.extraClassPath' to '/u01/app/oracle/product/12.1.0/dbhome_12102/jdbc/lib/ojdbc7.jar' as a work-around.
Spark context available as sc.
16/07/03 16:14:10 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/07/03 16:14:11 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/07/03 16:14:24 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
16/07/03 16:14:24 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
16/07/03 16:14:28 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/07/03 16:14:28 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
SQL context available as sqlContext.
First, we create a data frame:
scala> val employees = sqlContext.load("jdbc", Map("url" -> "jdbc:oracle:thin:zohar/zohar@//localhost:1521/single", "dbtable" -> "hr.employees"))
warning: there were 1 deprecation warning(s); re-run with -deprecation for details
employees: org.apache.spark.sql.DataFrame = [EMPLOYEE_ID: decimal(6,0), FIRST_NAME: string, LAST_NAME: string, EMAIL: string, PHONE_NUMBER: string, HIRE_DATE: timestamp, JOB_ID: string, SALARY: decimal(8,2), COMMISSION_PCT: decimal(2,2), MANAGER_ID: decimal(6,0), DEPARTMENT_ID: decimal(4,0)]
Now, we can count the rows:
scala> employees.count() res0: Long = 107
Show the schema:
scala> employees.printSchema root |-- EMPLOYEE_ID: decimal(6,0) (nullable = false) |-- FIRST_NAME: string (nullable = true) |-- LAST_NAME: string (nullable = false) |-- EMAIL: string (nullable = false) |-- PHONE_NUMBER: string (nullable = true) |-- HIRE_DATE: timestamp (nullable = false) |-- JOB_ID: string (nullable = false) |-- SALARY: decimal(8,2) (nullable = true) |-- COMMISSION_PCT: decimal(2,2) (nullable = true) |-- MANAGER_ID: decimal(6,0) (nullable = true) |-- DEPARTMENT_ID: decimal(4,0) (nullable = true)
Or even query the data
scala> employees.show +-----------+-----------+----------+--------+------------+--------------------+----------+--------+--------------+----------+-------------+ |EMPLOYEE_ID| FIRST_NAME| LAST_NAME| EMAIL|PHONE_NUMBER| HIRE_DATE| JOB_ID| SALARY|COMMISSION_PCT|MANAGER_ID|DEPARTMENT_ID| +-----------+-----------+----------+--------+------------+--------------------+----------+--------+--------------+----------+-------------+ | 100| Steven| King| SKING|515.123.4567|2003-06-17 00:00:...| AD_PRES|24000.00| null| null| 90| | 101| Neena| Kochhar|NKOCHHAR|515.123.4568|2005-09-21 00:00:...| AD_VP|17000.00| null| 100| 90| | 102| Lex| De Haan| LDEHAAN|515.123.4569|2001-01-13 00:00:...| AD_VP|17000.00| null| 100| 90| | 103| Alexander| Hunold| AHUNOLD|590.423.4567|2006-01-03 00:00:...| IT_PROG| 9000.00| null| 102| 60| | 104| Bruce| Ernst| BERNST|590.423.4568|2007-05-21 00:00:...| IT_PROG| 6000.00| null| 103| 60| | 105| David| Austin| DAUSTIN|590.423.4569|2005-06-25 00:00:...| IT_PROG| 4800.00| null| 103| 60| | 106| Valli| Pataballa|VPATABAL|590.423.4560|2006-02-05 00:00:...| IT_PROG| 4800.00| null| 103| 60| | 107| Diana| Lorentz|DLORENTZ|590.423.5567|2007-02-07 00:00:...| IT_PROG| 4200.00| null| 103| 60| | 108| Nancy| Greenberg|NGREENBE|515.124.4569|2002-08-17 00:00:...| FI_MGR|12008.00| null| 101| 100| | 109| Daniel| Faviet| DFAVIET|515.124.4169|2002-08-16 00:00:...|FI_ACCOUNT| 9000.00| null| 108| 100| | 110| John| Chen| JCHEN|515.124.4269|2005-09-28 00:00:...|FI_ACCOUNT| 8200.00| null| 108| 100| | 111| Ismael| Sciarra|ISCIARRA|515.124.4369|2005-09-30 00:00:...|FI_ACCOUNT| 7700.00| null| 108| 100| | 112|Jose Manuel| Urman| JMURMAN|515.124.4469|2006-03-07 00:00:...|FI_ACCOUNT| 7800.00| null| 108| 100| | 113| Luis| Popp| LPOPP|515.124.4567|2007-12-07 00:00:...|FI_ACCOUNT| 6900.00| null| 108| 100| | 114| Den| Raphaely|DRAPHEAL|515.127.4561|2002-12-07 00:00:...| PU_MAN|11000.00| null| 100| 30| | 115| Alexander| Khoo| AKHOO|515.127.4562|2003-05-18 00:00:...| PU_CLERK| 3100.00| null| 114| 30| | 116| Shelli| Baida| SBAIDA|515.127.4563|2005-12-24 00:00:...| PU_CLERK| 2900.00| null| 114| 30| | 117| Sigal| Tobias| STOBIAS|515.127.4564|2005-07-24 00:00:...| PU_CLERK| 2800.00| null| 114| 30| | 118| Guy| Himuro| GHIMURO|515.127.4565|2006-11-15 00:00:...| PU_CLERK| 2600.00| null| 114| 30| | 119| Karen|Colmenares|KCOLMENA|515.127.4566|2007-08-10 00:00:...| PU_CLERK| 2500.00| null| 114| 30| +-----------+-----------+----------+--------+------------+--------------------+----------+--------+--------------+----------+-------------+ only showing top 20 rows
We can even start manipulating the data, and converting it to RDD:
scala> employees.filter("EMPLOYEE_ID = 101").show
+-----------+----------+---------+--------+------------+--------------------+------+--------+--------------+----------+-------------+
|EMPLOYEE_ID|FIRST_NAME|LAST_NAME| EMAIL|PHONE_NUMBER| HIRE_DATE|JOB_ID| SALARY|COMMISSION_PCT|MANAGER_ID|DEPARTMENT_ID|
+-----------+----------+---------+--------+------------+--------------------+------+--------+--------------+----------+-------------+
| 101| Neena| Kochhar|NKOCHHAR|515.123.4568|2005-09-21 00:00:...| AD_VP|17000.00| null| 100| 90|
+-----------+----------+---------+--------+------------+--------------------+------+--------+--------------+----------+-------------+
Convert to RDD:
scala> val rdd = employees.filter("JOB_ID = 'FI_ACCOUNT'").rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[106] at rdd at <console>:27
scala> rdd.collect
res37: Array[org.apache.spark.sql.Row] = Array([109,Daniel,Faviet,DFAVIET,515.124.4169,2002-08-16 00:00:00.0,FI_ACCOUNT,9000.00,null,108,100], [110,John,Chen,JCHEN,515.124.4269,2005-09-28 00:00:00.0,FI_ACCOUNT,8200.00,null,108,100], [111,Ismael,Sciarra,ISCIARRA,515.124.4369,2005-09-30 00:00:00.0,FI_ACCOUNT,7700.00,null,108,100], [112,Jose Manuel,Urman,JMURMAN,515.124.4469,2006-03-07 00:00:00.0,FI_ACCOUNT,7800.00,null,108,100], [113,Luis,Popp,LPOPP,515.124.4567,2007-12-07 00:00:00.0,FI_ACCOUNT,6900.00,null,108,100])
For more information, you can use Spark documeation: https://spark.apache.org/docs/latest/api/python/pyspark.sql.html (this is for python) and http://spark.apache.org/docs/latest/sql-programming-guide.html
Summary
This is not all we can do with Spark SQL – we can also join RDDs, intersect them and more – but I think this is enough for one post. This was about the basics, and maybe in a later post I can show some one functionality – if you find this interesting.
Spark has great potential in the big data world – it’s been one of the driving forces behind big data in the last couple of years. If you’re a DBA and hadn’t had the chance to go into big data – Spark is a great place to start…


{kind=link}
Thanks for sharing
Zohar, thanks for sharing your experience. Nice and easy to follow. Considering your Oracle and Spark experience can you please share how to achieve a better performance of Oracle queries using Spark with Oracle. I’m trying to see if it is possible for well optimized Oracle queries to run faster on a Spark cluster. I know most MySQL queries run faster on Spark due to partitioning but can’t find anything on this subject about Oracle
I didn’t see any Oracle query optimization done in Spark – mostly because it’s JDBC connection and massive output of data is not really partitioned efficiently (as far as I could see – I didn’t check Spark 2.0 yet).
The only tool I saw that did nice optimization for Oracle massive data extract was Sqoop – where the data is being partitioned and scanned by extents (using rowids) – so no block will be scanned twice. See here: https://github.com/apache/sqoop/blob/a0b730c77e297a62909063289ef37a2b993ff5e1/src/java/org/apache/sqoop/manager/oracle/OraOopOracleDataChunkExtent.java
I’ll try to look at Oracle-Spark optimization methods later – to see if there’s anything I can find to help, and post it here.. 🙂
which driver you are using ; I am getting SQLException: No suitable driver exception. how to set up driver
You might want to try the ojdbc7.jar from this project: https://github.com/sanjeevbadgeville/Spark2-H2O-R-Zeppelin
how to pass user name and password of oracle to Spark Command.
warning: there were 1 deprecation warning(s); re-run with -deprecation for details
java.sql.SQLException: ORA-01017: invalid username/password; logon denied
You’re probably passing the wrong username and/or password (this is what ORA-01017 says).
Password is being passed through the URL. In this example, the username is “myuser” and the password is “mypassword”:
scala> val employees = sqlContext.load("jdbc", Map("url" -> "jdbc:oracle:thin:myuser/mypassword@//localhost:1521/single", "dbtable" -> "hr.employees"))Thanks , Now I am able to connect.
i am able to do select
Can you provide me Insert a record query from Spark to Oracle.
Can we access Oracle from DataFrame also ?
Yes, you can use Dataframes – if you use dataframes, you can do this:
df.write.mode("append").jdbc("jdbc:oracle:thin:zohar/zohar@//localhost:1521/single", "hr.employees", connectionProperties)I’ll try to create a short demo on that soon.
Hi,
Thanks for the reply, I am in the middle of implementation for Insert a record in oracle from Spark.
it will be ,helpful to me.
if you post the insert logic.
i have followed your the above ,Using spark 1.3.0.I am getting issues while loading DF…
17/10/13 17:33:03 INFO DAGScheduler: Job 0 failed: collect at SparkPlan.scala:83, took 3.208627 s
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, vprv5006.egd.enbridge.com): java.sql.SQLException: No suitable driver found for jdbc:oracle:thinxxxxxxxxxxxxxxxxxxxxxxxxxxxx
at java.sql.DriverManager.getConnection(DriverManager.java:596)
at java.sql.DriverManager.getConnection(DriverManager.java:233)
I am ble to print schema val workorder = sqlContext.load(“jdbc”, Map(“url” -> “jdbc:oracle:thin:XXXXXXXXXXXXXXXXXXXXXx”,”driver” -> “oracle.jdbc.driver.OracleDriver”, “dbtable” -> “xxxx.xx”))
but if i perform count or collect i get htis issue
Do you have a driver for Oracle JDBC on your server? the error you’re getting is basically: “No suitable driver found for jdbc:oracle:thin”